De acordo com as Leis 12.965/2014 e 13.709/2018, que regulam o uso da Internet e o tratamento de dados pessoais no Brasil, ao me inscrever na newsletter do portal DICAS-L, autorizo o envio de notificações por e-mail ou outros meios e declaro estar ciente e concordar com seus Termos de Uso e Política de Privacidade.
CUDA - Programe a sua NVIDIA
Colaboração: Alessandro de Oliveira Faria
Data de Publicação: 05 de January de 2010
Na revista Linux Magazine deste mês (exemplar número 61, dezembro/2009) publiquei um artigo sobre visão computacional onde menciono a sua aplicabilidade em projetos de realidade aumentada, robótica e biometria que utilizam reconhecimento de padrões e processamento de imagens em tempo real.
Aplicar processos de visão computacional em fluxos de vídeo ao vivo é uma tarefa morosa devido ao grande consumo de processamento matemático. Este custo computacional é grande mesmo para os processadores atuais, pois analisar e processar imagens ao vivo significa aplicar complexos algoritmos em 30 quadros com dimensões 640x480 por segundo. Neste cenário os chips gráficos serão imprescindíveis para um ganho significativo na performance destes aplicativos.
Vale a pena mencionar que, na teoria, quanto mais núcleos tem uma CPU, maior o número de transístores e, por consequência, melhor sua performance. Mas, na prática, isto não acontece pelo principal motivo: o software está anos atrás do hardware. Uma CPU com 4 núcleos pode perder em performance nos games pelo fato do software ser otimizados para 2 núcleos. A programação em paralelo para 4 núcleos significa aumentar o problema, sem contar na otimização dos compiladores para fazer uso do paralelismo.
Assim entendemos a aquisição pela Petrobras do supercomputador baseado em GPU (chips gráficos encontrados nas placas de vídeo). O seu poder de processamento é de 250 teraflops e caracterizado como 16° maior supercomputador do planeta. Este equipamento auxiliará simulações geofísicas cujo objetivo é "aprimorar a visualização das camadas geológicas do subsolo para suportar a exploração e produção de petróleo", segundo o anúncio da Bull à imprensa.
Baseada na maravilhosa tecnologia NVIDIA CUDA, o seu uso ajudará também a melhorar o desempenho das análises sísmicas. Para isto a Petrobras investiu em um cluster baseado em GPUs composto de 190 processadores paralelos NVIDIA Tesla.
NVIDIA CUDA é uma arquitetura de computação paralela de propósito geral que tira proveito do mecanismo de computação paralela das unidades de processamento gráfico (GPUs) NVIDIA para resolver muitos problemas computacionais complexos em uma fração do tempo necessário em uma CPU.
A expectativa da Petrobras é de que a performance das GPUs aumente, e pretende atingir uma potência superior a 400 teraflops no seu data center. Para entender melhor a diferença fundamental entre os processadores convencionais (CPUs) e os chipsets de vídeo (GPUs), digamos que as CPUs são otimizadas para cálculos sequenciais já as GPUs são otimizadas para cálculos intensamente paralelos.
No passado ficava muito clara esta diferença entres os chips, pois as placas 3D processavam muitos triângulos por segundo (3df Voodoo). Mas com o surgimento dos shaders (rotinas criadas para tarefas específicas na criação de cenas), as GPUs passaram a ganhar capacidade de processamento sequencial como as CPUs. Os shaders permite procedimentos de sombreamento e/ou iluminação, dando assim liberdade aos programadores artistas. O termo shader é originado do programa RenderMan, criado pela Pixar no final da década de 80.
Sendo mais objetivo, uma GeForce 9600 GT apresenta uma performance seis vezes superior comparado com um processador Core 2 Duo E6700 na tarefa de codificação de vídeos H.264. Em um trailer na resolução 1920 x 1080 pixels, a codificação com uma GPUs levou aproximadamente 3:36 minutos, já a codificação com processos convencionais levaram em torno de 17:17 minutos. Logo, é possível utilizar a tecnologia NVIDIA CUDA em codificações e decodificações de vídeos, como também em aplicações científicas de alta performance.
O CUDA permite utilizar recursos das placas NVIDIA utilizando chamadas em C (C for CUDA, compilador nvcc), o que torna o processo como um todo relativamente fácil para os BONS PROGRAMADORES. Existem também abstração para a linguagem Java (jCUDA), C# (CUDA.NET) e também Python (PyCUDA).
O processamento paralelo da GPU permite executar-se mais ações com menos tráfego de informações em barramentos, usando a área de cache comum e acesso direto a memória. Com a utilização da API (OpenMM), será possível desenvolver cálculos moleculares de maneira simples e integrada com as GPUs. Logo o trabalho que uma CPU processa em dias, sera processado em horas!
Os especialistas no segmento, dizem que, para o futuro, os processadores terão unidade processamento paralelo integrado, executando assim múltiplas funções. Então acredito que a GPU será outro processador auxiliar, como aconteceu com o coprocessador matemático integrado nos processadores 486. Bons tempos quando eu e o meu sócio comprávamos coprocessadores matemáticos para instalar em placas com processadores 386...
Download e instalação
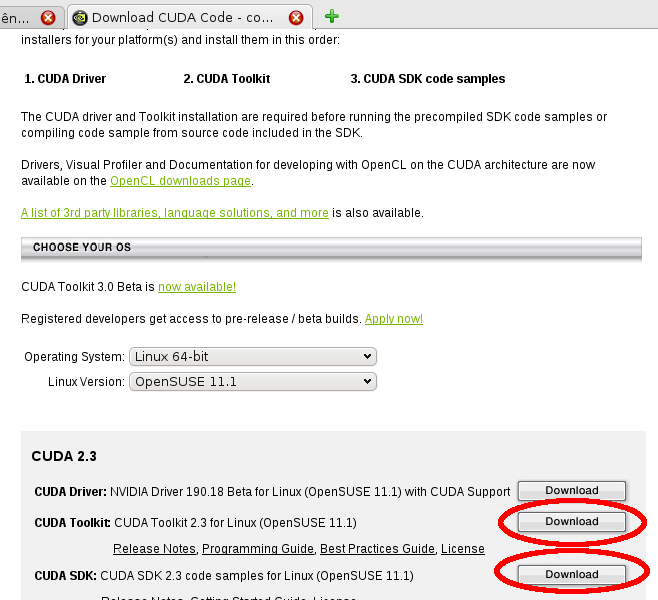
O download dos arquivos necessários para trabalhar com a tecnologia CUDA deverá ser obtido no endereço: http://www.nvidia.com/object/cuda_get.html
O arquivo cudatoolkit_2.3_linux_64_suse11.1.run contém as ferramentos de desenvolvimento (compilador entre outros). Já o arquivo cudasdk_2.3_linux.run, como o próprio nome diz, são os arquivos de desenvolvimento contendo exemplos. A seguir o link direto para download para a distribuição OpenSUSE 11.1/2 64 bits (as demais distribuições, selecionar no link de download).
- http://www.nvidia.com/object/thankyou.html?url=/compute/cuda/2_3/toolkit/cudatoolkit_2.3_linux_64_suse11.1.run
- http://www.nvidia.com/object/thankyou.html?url=/compute/cuda/2_3/sdk/cudasdk_2.3_linux.run
ATENÇÃO: Ressalto que este documento parte do princípio que o equipamento possui instalado o driver NVIDIA 190 ou superior com suporte ao CUDA.
 |
Para instalar o pacote CUDA Toolkit, execute o arquivo
cudatoolkit_2.3_linux_64_suse11.1.run:
# sh cudatoolkit_2.3_linux_64_suse11.1.run Enter install path (default /usr/local/cuda, '/cuda' will be appended): "man/man3/cudaBindTexture.3" -> "/usr/local/cuda/man/man3/cudaBindTexture.3" "man/man3/cuMemsetD2D32.3" -> "/usr/local/cuda/man/man3/cuMemsetD2D32.3" "man/man3/NumChannels.3" -> "/usr/local/cuda/man/man3/NumChannels.3" "man/man3/cudaD3D9ResourceSetMapFlags.3" -> "/usr/local/cuda/man/man3/cudaD3D9ResourceSetMapFlags.3" "man/man3/CUDA_ERROR_INVALID_HANDLE.3" -> "/usr/local/cuda/man/man3/CUDA_ERROR_INVALID_HANDLE.3" "man/man3/cudaDeviceProp.3" -> "/usr/local/cuda/man/man3/cudaDeviceProp.3" "man/man3/CU_MEMHOSTALLOC_PORTABLE.3" -> "/usr/local/cuda/man/man3/CU_MEMHOSTALLOC_PORTABLE.3" ======================================== * Please make sure your PATH includes /usr/local/cuda/bin * Please make sure your LD_LIBRARY_PATH * for 32-bit Linux distributions includes /usr/local/cuda/lib * for 64-bit Linux distributions includes /usr/local/cuda/lib64 * OR * for 32-bit Linux distributions add /usr/local/cuda/lib * for 64-bit Linux distributions add /usr/local/cuda/lib64 * to /etc/ld.so.conf and run ldconfig as root * Please read the release notes in /usr/local/cuda/doc/ * To uninstall CUDA, delete /usr/local/cuda * Installation Complete
Insira a linha a seguir no arquivo /etc/ld.so.conf ou acrescente na variável de ambiente LD_LIBRARY_PATH:
/usr/local/cuda/lib64
Devemos também incluir a pasta bin na variável PATH:
# export PATH=$PATH:/usr/local/cuda/bin
Repita o procedimento para instalar o pacote CUDA SDK, executando o arquivo cudasdk_2.3_linux.run2:
$ sh cudasdk_2.3_linux.run
ATENÇÃO: Para os compiladores gcc 4.3 ou superiores, antes de compilar os exemplos, alterar a linha 126 do arquivo common.mk conforme o exemplo a seguir.
$ vi ~/NVIDIA_GPU_Computing_SDK/C/common/common.mk
E modificar a linha 126:
NVCCFLAGS += --compiler-options -fno-strict-aliasing --compiler-options -fno-inline
Para compilar os exemplos, basta executar os comandos a seguir:
$ cd ~/NVIDIA_GPU_Computing_SDK/C $ make
Teste os exemplos:
$ cd ~/NVIDIA_GPU_Computing_SDK/C/bin/linux/release
$ ./deviceQuery
CUDA Device Query (Runtime API) version (CUDART static linking)
There is 1 device supporting CUDA
Device 0: "GeForce 8400M GS"
CUDA Driver Version: 2.30
CUDA Runtime Version: 2.30
CUDA Capability Major revision number: 1
CUDA Capability Minor revision number: 1
Total amount of global memory: 268107776 bytes
Number of multiprocessors: 2
Number of cores: 16
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes
Total number of registers available per block: 8192
Warp size: 32
Maximum number of threads per block: 512
Maximum sizes of each dimension of a block: 512 x 512 x 64
Maximum sizes of each dimension of a grid: 65535 x 65535 x 1
Maximum memory pitch: 262144 bytes
Texture alignment: 256 bytes
Clock rate: 0.80 GHz
Concurrent copy and execution: Yes
Run time limit on kernels: Yes
Integrated: No
Support host page-locked memory mapping: No
Compute mode: Default (multiple host threads
can use this device simultaneously)
Test PASSED
Press ENTER to exit...
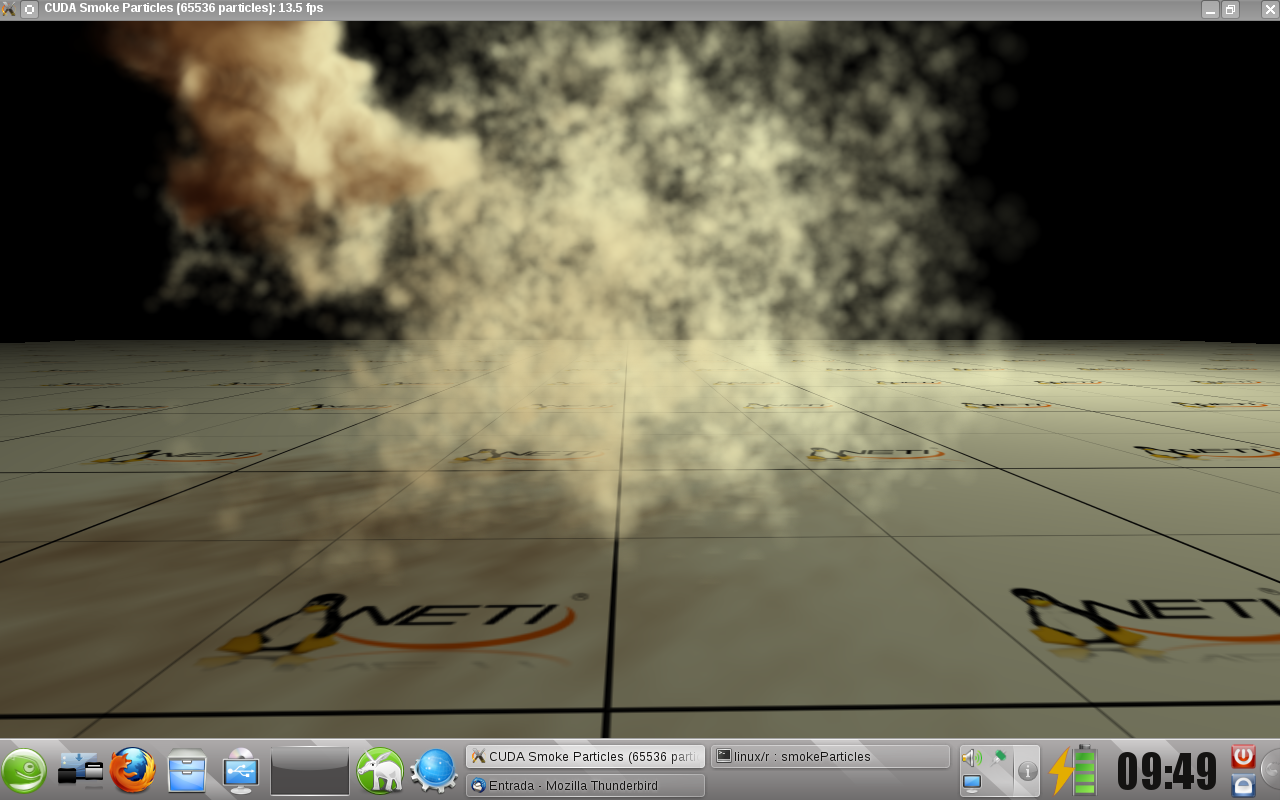
Algumas imagens de programas exemplos utilizando a tecnologia CUBA:
 |
 |
Para usar a força (ler os fontes), basta ler os exemplos na pasta ~/NVIDIA_GPU_Computing_SDK/C/src.
 |
Publicado originalmente no site Viva o Linux
Alessandro Faria é sócio-proprietário da empresa NETi TECNOLOGIA fundada em Junho de 1996 (http://www.netitec.com.br), empresa especializada em desenvolvimento de software e soluções biométricas, Consultor Biométrico na tecnologia de reconhecimento facial, atuando na área de tecnologia desde 1986 assim propiciando ao mercado soluções em software. Leva o Linux a sério desde 1998 com desenvolvimento de soluções open-source, membro colaborador da comunidade Viva O Linux, mantenedor da biblioteca open-source de vídeo captura entre outros projetos.