De acordo com as Leis 12.965/2014 e 13.709/2018, que regulam o uso da Internet e o tratamento de dados pessoais no Brasil, ao me inscrever na newsletter do portal DICAS-L, autorizo o envio de notificações por e-mail ou outros meios e declaro estar ciente e concordar com seus Termos de Uso e Política de Privacidade.
O Padrão RSS - A luz no fim do túnel
Colaboração: Rubens Queiroz de Almeida
Data de Publicação: 22 de Setembro de 2005
A informação disponível na Internet tem crescido vertiginosamente nos últimos quinze anos. No início, quando a Internet era não mais do que uma vila do interior, era possível conhecer praticamente todos os sites importantes. Neste tempo, final dos anos 80 até a explosão da Web, de 1993 em diante, não existiam indexadores de conteúdo e as listas eletrônicas, ainda não infestadas pela praga do spam, eram fonte valiosíssima de informação. A primeira revolução na busca de informação na Internet foi o software Gopher, criado em 1991. Seu reinado foi extremamente curto. A Web, com sua infinidade de recursos e facilidade de uso, rapidamente colocou os servidores Gopher de todo o mundo no rodapé da história da Internet. Com a Web rapidamente apareceram os primeiros serviços de catalogação do Internet. O primeiro deles foi o Yahoo, seguido por diversos outros como Altavista, Excite, Infoseek, chegando ao mais famoso e popular de todos, o Google.
Nestes quinze anos a Internet deixou de ser um luxo de alguns poucos, principalmente instituições educacionais e governamentais, para ser um aspecto presente na vida de praticamente todos. Da pureza dos dias originais aos dias de hoje, muita coisa mudou. A quantidade de informação disponível aumentou de forma exponencial. Os desafios para indexar com qualidade esta enorme quantidade de informação também cresceram. O uso comercial da Web se tornou um complicador adicional, pois para obter a primeira posição no ranking dos mecanismos de busca se criou um clima de vale tudo, criando uma corrida de gato e rato entre os mecanismos de busca e empresas com presença na Internet. Os primeiros tentando manter a pureza e relevância de seus índices e os demais tentando, por todas as formas, burlar os mecanismos de indexação para obterem maior visibilidade. A tragédia maior, entretanto, ainda estava por vir: o spam, ou mensagens de email não solicitadas.
O correio eletrônico, por ser de fácil criação e distribuição, logo se tornou o inferno maior da vida dos internautas. Diariamente circulam bilhões de mensagens pela Internet com o objetivo de divulgar todos os tipos de produtos. Não raro nos deparamos com dezenas e até mesmo centenas de mensagens de spam em nossas caixas de correio eletrônico.
Qual então é a situação atual? A quantidade de informações disponível na Web tornou inviável a organização dos sites preferidos por meio das bookmarks pessoais. Da mesma forma é inviável visitar todos os sites de interesse. São tantos e simplesmente não há tempo. Acabamos não visitando nenhum e, paradoxalmente, em um mundo com tal excesso de informação, ficamos desatualizados. O email, pelo mau uso e pela quantidade absurda de mensagens lixo, também deixou de ser uma alternativa confortável para obtenção de informações.
O Padrão RSS
A solução para tratar adequadamente o excesso de informação da Web veio na forma de um novo padrão, baseado na linguagem XML de marcação, chamado RSS. A sigla RSS pode significar Rich Site Summary ou RDF Site Summary e também Really Simple Syndication. Na prática o resultado é o mesmo. A proposta deste padrão é criar uma forma através da qual um site possa divulgar para o mundo as suas novidades. Estas notícias são gravadas, no formato XML, em um arquivo que pode ser lido e interpretado, por diversos tipos de programas.
A grande revolução é que o padrão RSS coloca o usuário de volta no comando. Ele seleciona as notícias que lhe interessam e monta o seu boletim de noticias pessoal, constantemente atualizado e contendo apenas os assuntos de maior relevância segundo sua ótica.
Bloglines
Esta é uma idéia muito interessante. porém, às vezes, de difícil compreensão. Para melhor ilustrar toda esta riqueza, nada melhor do que explicar o funcionamento de um serviço gratuito chamado Bloglines. Embora o nome do serviço seja Bloglines, o site agrega notícias de quaisquer fontes que disponibilizem seus dados no formato RSS, inclusive, é claro, os blogs.
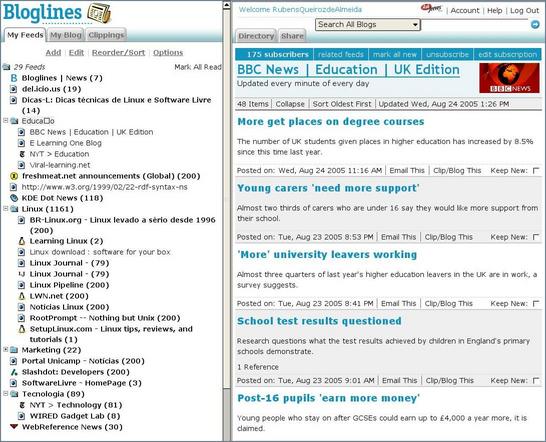
Como se pode ver na imagem acima, foi feita uma seleção de diversas fontes de informação que refletem os meus interesses profissionais. São fontes de dados do jornal New York Times, BBC e diversos sites de notícias nacionais e internacionais. As notícias foram agrupadas em tópicos, como Educação, Linux, Marketing, Tecnologia, etc. Este agrupamento é feito pelo usuário do serviço. De forma resumida, foi montado um jornal pessoal a partir de diversas fontes. As pastas, que refletem os temas principais, podem ser abertas, quando então as fontes individuais de notícias são exibidas com mais detalhes, ou então se pode acessar diretamente o tópico principal. Neste caso é feita uma agregação dos resultados de todas as fontes de notícias em uma única página. O leitor poderá então selecionar seus artigos de interesse a partir dos títulos e sumários das notícias.
Outra característica interessante deste serviço é o controle que nos oferece das notícias já lidas. Desta forma, ao acessar o serviço diariamente, ve-se apenas as novidades, os artigos que foram criados após a última visita.
O serviço Bloglines oferece também a possibilidade de importar ou exportar nossas preferências. Esta opção consiste na criação de um arquivo XML com todas as informações relativas às nossas preferências, que podem ser repassadas a terceiros ou mesmo usadas em outros serviços.
As informações disponíveis por meio de canais RSS podem ser acessadas de diversas formas. O serviço Bloglines é apenas uma delas, certamente muito criativa e útil.
Clientes de Correio Eletrônico: Mozilla Thunderbird
O que é necessário para acessar estas informações é apenas um programa de computador que consigar ler e interpretar o formato RSS. A figura a seguir ilustra a leitura de notícias RSS com o programa Mozilla-Thunderbird, onde as novidades são exibidas da mesma forma que uma mensagem normal de correio eletrônico.
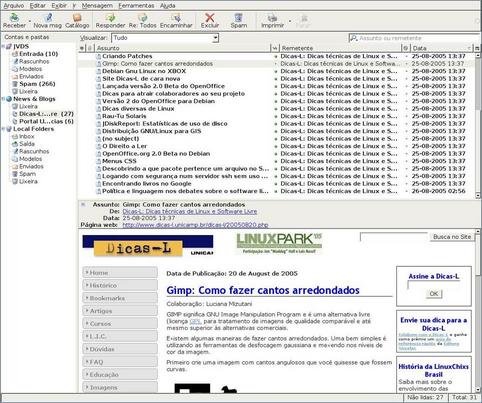 Janela do leitor de emails Mozilla Thunderbird
Janela do leitor de emails Mozilla Thunderbird
Mozilla Firefox
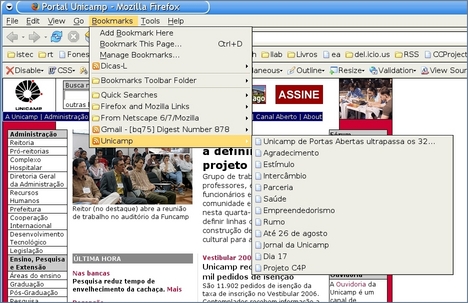
Uma outra forma de acesso a canais RSS nos é oferecida pelo browser Mozilla Firefox, por meio do recurso conhecido como Live Bookmarks, ou bookmarks dinâmicas. Para se criar uma bookmark dinâmica basta apontar o endereço para um canal RSS. Sempre que se acessar esta bookmark, o resultado será exibido por meio de uma consulta feita em tempo real ao endereço onde se encontra o canal de notícias do site. A figura a seguir ilustra o uso deste recurso, com a exibição do canal de notícias do site da Unicamp.
Sites de Notícias
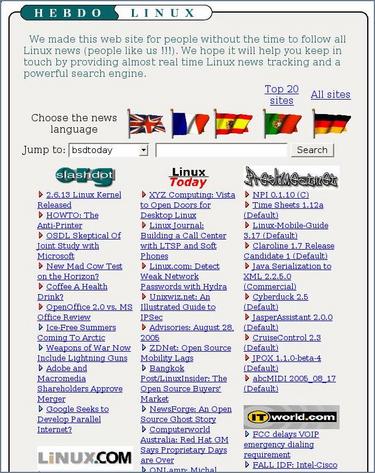
Existem hoje diversos sites que não se ocupam em criar conteúdo próprio. Realizam apenas uma agregação de conteúdos já existentes. O site Hebdolinux é um exemplo de site com este objetivo, contendo apenas uma página que por suas vez obtém seus dados de diversos outros sites de informações por meio das informações contidas em arquivos RSS.
Este padrão, embora ainda relativamente desconhecido de grande parte dos usuários da Internet, já é suportado por um grande número de sites. No site do jornal americando The New York Times, nós encontramos a informação sobre os canais RSS, bem ao final da página, como podemos ver na figura a seguir. Normalmente esta informação é destacada pela imagem destacada com o círculo vermelho.
 Feeds RSS New York Times
Feeds RSS New York Times
Sites de Busca para Canais RSS
Já existem serviços de busca para canais RSS. A imagem a seguir ilustra uma busca no serviço Syndic8 sobre o tema Distance Education
Considerações Finais
O padrão RSS, por seu poder e abrangência, merece um estudo mais detalhado. Para profissionais da área de educação, a distância e presencial, oferece um caminho eficiente para a atualização técnica e acompanhamento de tendências. A idéia principal é a do jornal personalizado, criado e atualizado diariamente de forma automática. As possibilidades são imensas e a cada dia novas aplicações aparecem. A luz no fim do túnel.
Referências
- RSS E AS NOVAS TENDÊNCIAS EM EDUCAÇÃO E TECNOLOGIA, por Suzana Gutierrez (http://www.icoletiva.com.br/icoletiva/secao.asp?tipo=artigos&id=95)
- Geeklog (http://www.geeklog.net/)
- Wikipedia: RSS File Format (http://en.wikipedia.org/wiki/RSS_%28file_format%29)
- WebReference.com/internet.com RSS Newsfeed (http://webreference.com/services/news/)
- Content feeds with RSS 2.0 (http://www-128.ibm.com/developerworks/xml/library/x-rss20/)
- Top 100 Most-Subscribed-To RSS Feeds (http://subhonker6.userland.com/rcsPublic/rssHotlist)
- Making An RSS Feed (http://searchenginewatch.com/sereport/print.php/34721_2175271)
- RSS Tutorial (http://www.mnot.net/rss/tutorial/)
- Feed Validator (http://feedvalidator.org/)
- Using Rich Site Summaries To Draw New Visitors (http://www.webtechniques.com/archives/2000/02/eisenzopf/)
- A Bright Future for Syndication (http://davenet.scripting.com/1999/09/03/theDarkSideOfSyndication)
- Wikipedia: The Gopher Protocol (http://en.wikipedia.org/wiki/Gopher_protocol)
Notas
- Uma linguagem de marcação sinaliza para um determinado programa como determinada informação deve ser exibida ou interpretada. Em HTML, se uma frase está circundada por <H1> e </H1>, isto indica ao browser que aquela frase é um cabeçalho de nivel 1 e deve ser grafada com maior destaque. Já a linguagem XML concentra-se antes de tudo na marcação do texto de acordo com seu significado. Na linguagem HTML as palavras Oliveira, como nome próprio e Oliveira denominando uma árvore, possuem exatamente o mesmo significado. Os mecanismos de busca não conseguem diferenciar uma palavra de outra. Já com a marcação XML cada uma destas palavras receberá o seu significado correto.
- Canais RSS são fontes de notícias criadas, geralmente de forma automática, por weblogs, sites de notícias e diversos outros tipos de serviços na Web.